The Business Impact of OpenAI o1

Quick Insights
- OpenAI just made an AI model that’s deliberately slower but thinks more carefully
- Its high costs forces businesses to think strategically about using it
- Companies will likely end up using both o1 and GPT-4o for different tasks
Introduction
Someone in 2020 looking at the AI landscape would have been puzzled by OpenAI’s latest move. Back then, every company was racing to make their AI models bigger and faster. But OpenAI just did something different: they made one slower (TechCrunch).
This might seem like a step backward. In technology, faster is usually better. But what OpenAI realized is that in some cases, taking more time to think leads to better results. Rather than releasing this as GPT-5, they “reset the counter back to 1” with their new model family (Zapier). The new model, o1, represents a fundamental shift in how AI systems work. Instead of racing to an answer, it prioritizes careful reasoning (OpenAI).
This creates an interesting situation for businesses. The standard way to evaluate AI models has been to look at their speed and cost per token. But o1 forces us to consider a new dimension: the quality of reasoning. It’s like the difference between hiring someone who works quickly but makes occasional mistakes, versus someone who works more slowly but rarely gets things wrong.
Understanding o1’s Business Value
The improvement in reasoning capability is dramatic. On International Math Olympiad problems, o1 scored 83% while GPT-4o only managed 13%. In competitive programming challenges, o1 reached the 89th percentile (Neoteric).
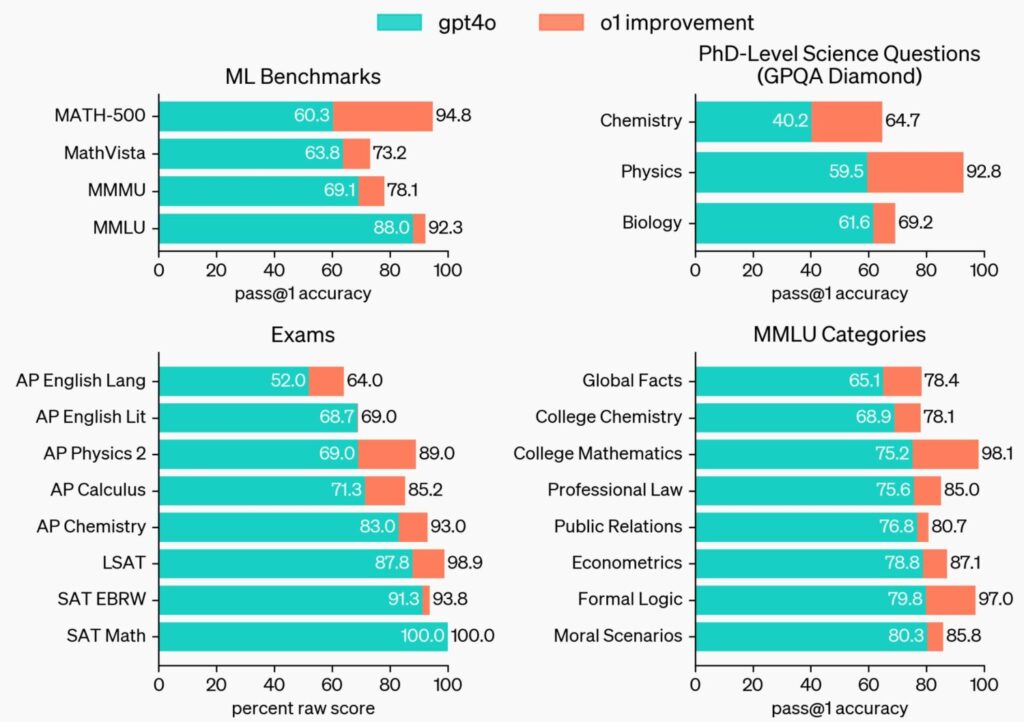
But what does this mean in practical terms? According to early testing, o1 excels at tasks that require deep analysis and multi-step thinking. For example, when analyzing legal briefs or solving complex LSAT logic games, o1 showed significantly better performance than previous models (TechCrunch).
This superiority stems from Chain of Thought (CoT) reasoning, where complex tasks are methodically analyzed. OpenAI’s research scientist Noam Brown explains that o1 is trained with reinforcement learning to “think” before responding via a private chain of thought (TechCrunch).
This capability extends beyond academic or theoretical problems. In real-world testing, o1 has demonstrated remarkable abilities across several demanding fields. Healthcare researchers have found it particularly valuable for annotating cell sequencing data, while physicists are using it to generate complex formulas for quantum optics. Software developers have seen significant improvements in building and debugging multi-step workflows (OpenAI).

From math competitions to coding challenges, o1 approaches human expert performance levels.
Each of these applications shares a common thread: they require careful, methodical thinking rather than quick responses. Processing time increases significantly – o1 can take over 10 seconds to answer some questions (TechCrunch). The model actually shows its work, displaying labels for each subtask it’s performing – like watching someone solve a complex math problem step by step.
The Cost of Innovation
The power of careful reasoning comes at a price. OpenAI’s pricing structure for o1 reflects a fundamental shift in how we value AI capabilities – paying more for thoughtful analysis rather than raw processing power. Here’s how the costs break down:
| Model | Price per million input tokens | Price per million output tokens |
| GPT-4o mini | $0.15 | $0.60 |
| o1-mini | $3 | $12 |
| GPT-4o | $5 | $15 |
| o1-preview | $15 | $60 |
To understand what these numbers mean in practice, let’s look at a real-world scenario. Consider translating a 20-page document, which typically contains about 50,000 tokens. Using o1, you’d need just one call to process this document, costing you $3.75. GPT-4o would need to break this into twelve separate calls due to its smaller context window, but would only cost $1.50 total. GPT-4o-mini offers the most economical option, requiring three calls and costing just 11 cents for the same translation (Neoteric).
The differences become even more striking at scale. A company processing thousands of documents would see their costs multiply dramatically. This is why OpenAI also released o1-mini, which offers a middle ground. While still more expensive than GPT-4o, it’s about 80% cheaper than the full o1 model (OpenAI).
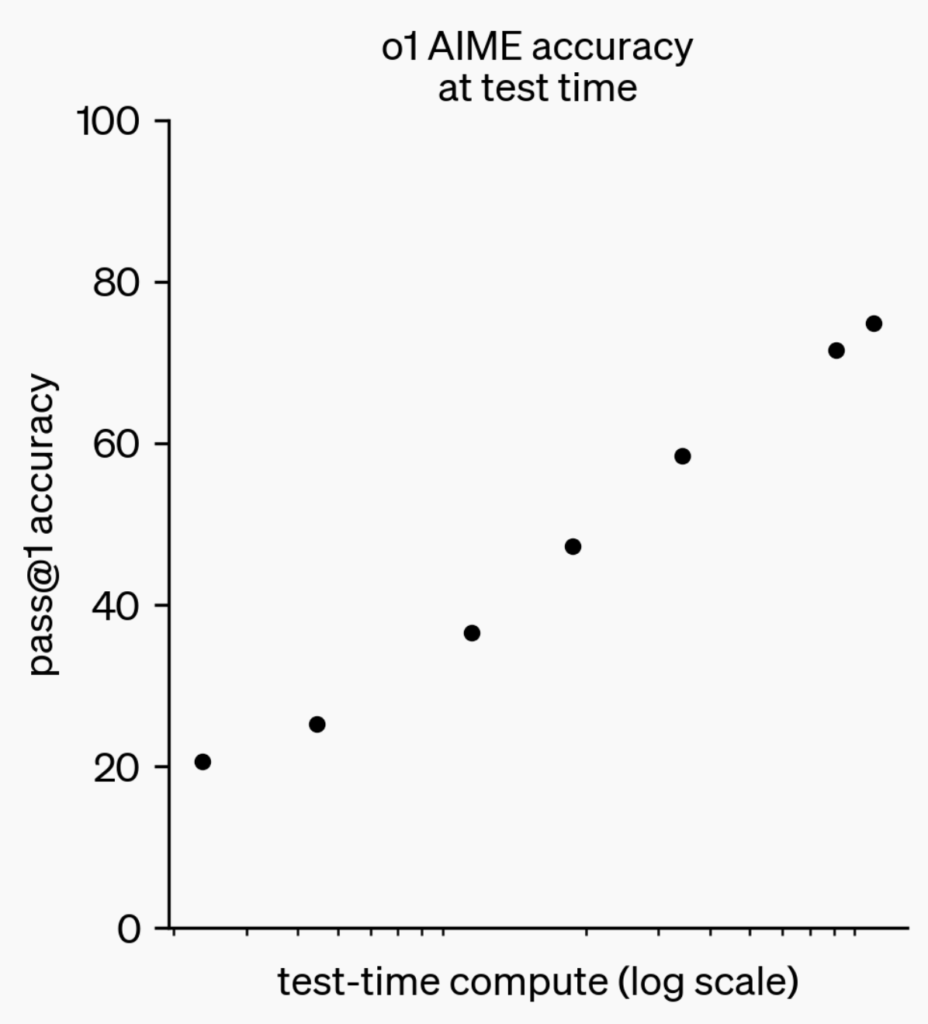
Performance improves with compute time, explaining o1’s deliberate approach to problem-solving.
Usage limitations add another dimension: OpenAI has set weekly rate limits of 30 messages for o1-preview and 50 for o1-mini (OpenAI). These constraints naturally guide organizations toward strategic deployment of o1’s capabilities.
Making the Right Choice
For businesses trying to decide when to use o1, the calculation might seem simple: Is the cost of a potential mistake in this task greater than the additional cost of using o1? But in practice, it’s more nuanced than that.
When to use o1: Complex analysis tasks
- Multi-step mathematical or logical problems
- Deep code analysis and architecture decisions
- Complex legal document analysis
- Scientific research requiring thorough analysis
When to use GPT-4o: Time-sensitive tasks
- Customer service responses
- Real-time data analysis
- Quick content generation
- Routine document processing
The most compelling use cases for o1 emerge in situations where accuracy and deep analysis matter more than speed. Healthcare researchers working with sensitive genetic data find the model’s careful approach invaluable. Physicists generating mathematical formulas for quantum optics benefit from its step-by-step reasoning. Development teams building complex workflows appreciate its ability to think through multiple steps and edge cases. Legal teams analyzing complex briefs have reported significant improvements in analysis quality (Neoteric).
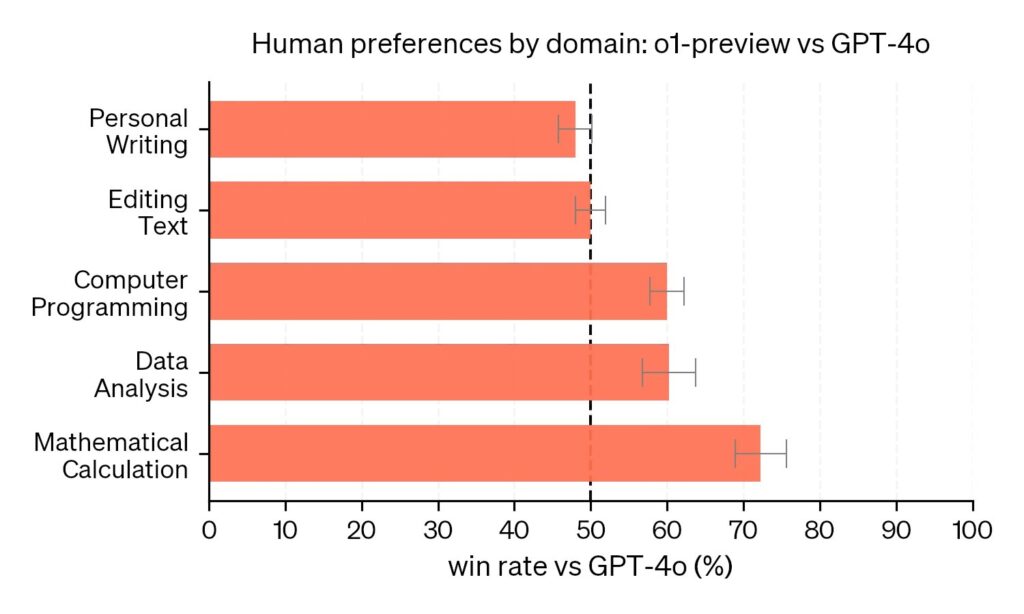
Users consistently prefer o1 for technical tasks while GPT-4o remains strong in writing.
However, o1 comes with important limitations. Unlike GPT-4o, it can’t currently browse the web for real-time information, upload and analyze files, or process images (TechCrunch). Think of it as a brilliant specialist consultant – brought in for specific, complex challenges.
GPT-4o remains optimal for general-purpose tasks like email writing and routine data analysis. When you need real-time information or need to handle multiple types of input like text, images, and audio simultaneously, GPT-4o’s speed makes it the obvious choice (Bind AI).
Most organizations will likely employ both models strategically. This mirrors effective resource allocation in any field – matching specialized tools to appropriate challenges.
Looking ahead
The introduction of o1 marks a shift in AI development priorities. The focus is shifting from raw capabilities to the quality of reasoning. This might lead to AI systems that can handle increasingly complex and nuanced tasks – but only if we’re willing to give them the time and resources to think carefully about problems.
For businesses, this means developing a new kind of literacy. Understanding AI is no longer just about knowing how to use these tools. It’s about understanding their varying capabilities, costs, and optimal use cases. The companies that develop this literacy first will have a significant advantage in deploying AI effectively.
The real impact of o1 isn’t just its superior reasoning capability. It’s that it forces businesses to think more carefully about how they use AI. And that might be its most valuable contribution of all.
The shift is reminiscent of something that happened in the early days of computers. At first, everyone focused on raw processing speed. But eventually, we realized that for many tasks, the limiting factor wasn’t the computer’s speed – it was how well we could tell it what to do. o1 might represent a similar shift in AI: from raw capability to careful reasoning. And just as with early computers, the companies that understand this change first will have a significant advantage.


